
Learning Engineer Agent
A multi-agent AI system that automates eLearning course creation through web research and live Socratic interviews with subject matter experts. Built to explore what agentic AI truly means for EdTech — and why human judgment remains irreplaceable in the loop.
Learning Engineer Agent: What Does Agentic AI Actually Mean for EdTech?
🚀 Learning Engineer Agent is live in private beta. Try it at learning-engineer-agent.web.app — sign in with Google and request a beta access code using the form on the access screen, or reach out to me directly.
Access is code-gated and intentionally limited. I am inviting a small cohort of early users — instructional designers, L&D practitioners, and EdTech researchers — who want to explore the system and are willing to share feedback. If you would like a code, request one here.
Watch the demo:
The Question That Started This
I have spent years in EdTech — building platforms, thinking about content, watching instructional designers struggle with the same fundamental problem over and over. Subject matter experts know things that are extraordinarily valuable. But getting that knowledge out of their heads and into a structured learning experience is slow, expensive, and deeply inefficient.
When large language models became genuinely capable, the obvious question was: can AI solve this? Can you give an AI a topic and get back a complete eLearning course?
The short answer is yes. The more interesting answer is: yes, but not in the way you might expect — and understanding the difference matters enormously for anyone building AI products in education.
This project is my attempt to build that system, and to think rigorously about what “agentic” actually means when the output needs to be trusted by real learners.
The Problem With “Just Give It a Topic”
The fantasy version of this product is simple. You type “Introduction to Negotiation for Sales Teams” and thirty minutes later a polished eLearning course lands in your inbox. No humans required.
I considered building exactly that. I decided not to.
Here is why. The hardest problem in eLearning is not content generation — it is knowledge elicitation. Subject matter experts have what researchers call tacit knowledge: things they know so deeply that they can no longer articulate them clearly. They skip steps they consider obvious. They forget what confused them when they were learning. They teach the theory while their actual expertise lives in the exceptions, the edge cases, the heuristics they have developed over years of practice.
An AI that researches a topic on the web and generates slides is not solving this problem. It is generating a reasonable-looking approximation of what the internet knows about a topic. That is useful for some things. For expert knowledge transfer, it is not enough.
The real product needed to do something harder: extract what the expert actually knows, not just what is written about their domain.
What Agentic AI Looks Like in Practice
Before building this, I spent time thinking carefully about what “agentic” means — not as a marketing term, but as an architectural commitment.
A truly autonomous agent receives a goal, decomposes it into tasks, executes those tasks, handles failures, and delivers an outcome — all without human intervention. This is technically achievable today for many narrow domains. For eLearning course creation, I believe it is the wrong design, at least for now.
The reason is not capability. It is trust and quality.
An eLearning course that will be used to train hundreds of employees cannot contain hallucinations, structural errors, or pedagogically unsound sequences — even minor ones. The cost of a mistake in training content is not a wrong search result that a user ignores. It is a misconception that propagates through an organisation. The stakes demand human judgment at critical junctures.
So instead of one long-running autonomous agent, I designed a system of agentic episodes — discrete bursts of intelligent autonomous behaviour, each producing a meaningful output that a human reviews before the next episode begins.
This distinction — agentic episodes versus long-running autonomous agents — is, I think, the most important architectural insight in this project.
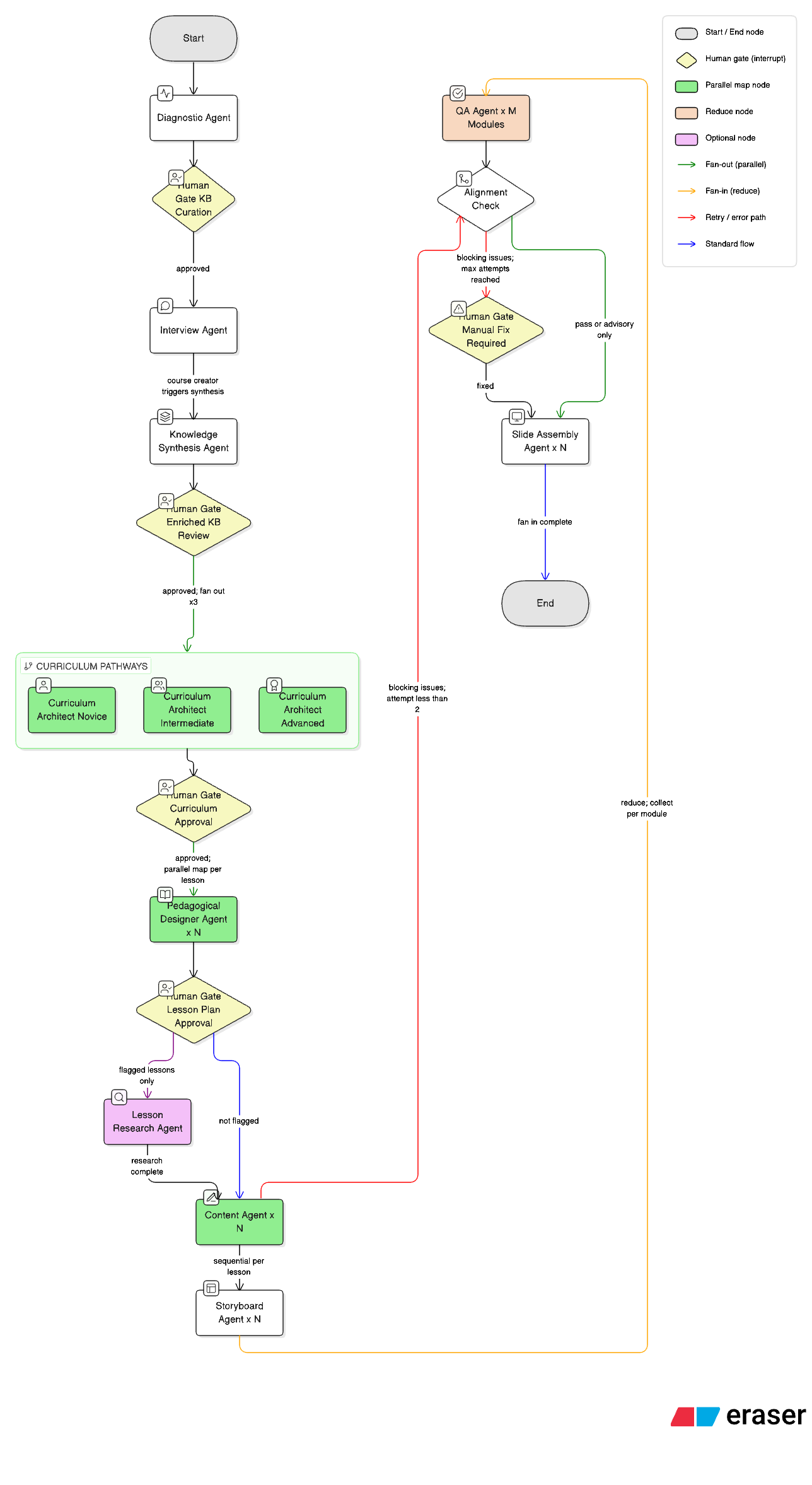
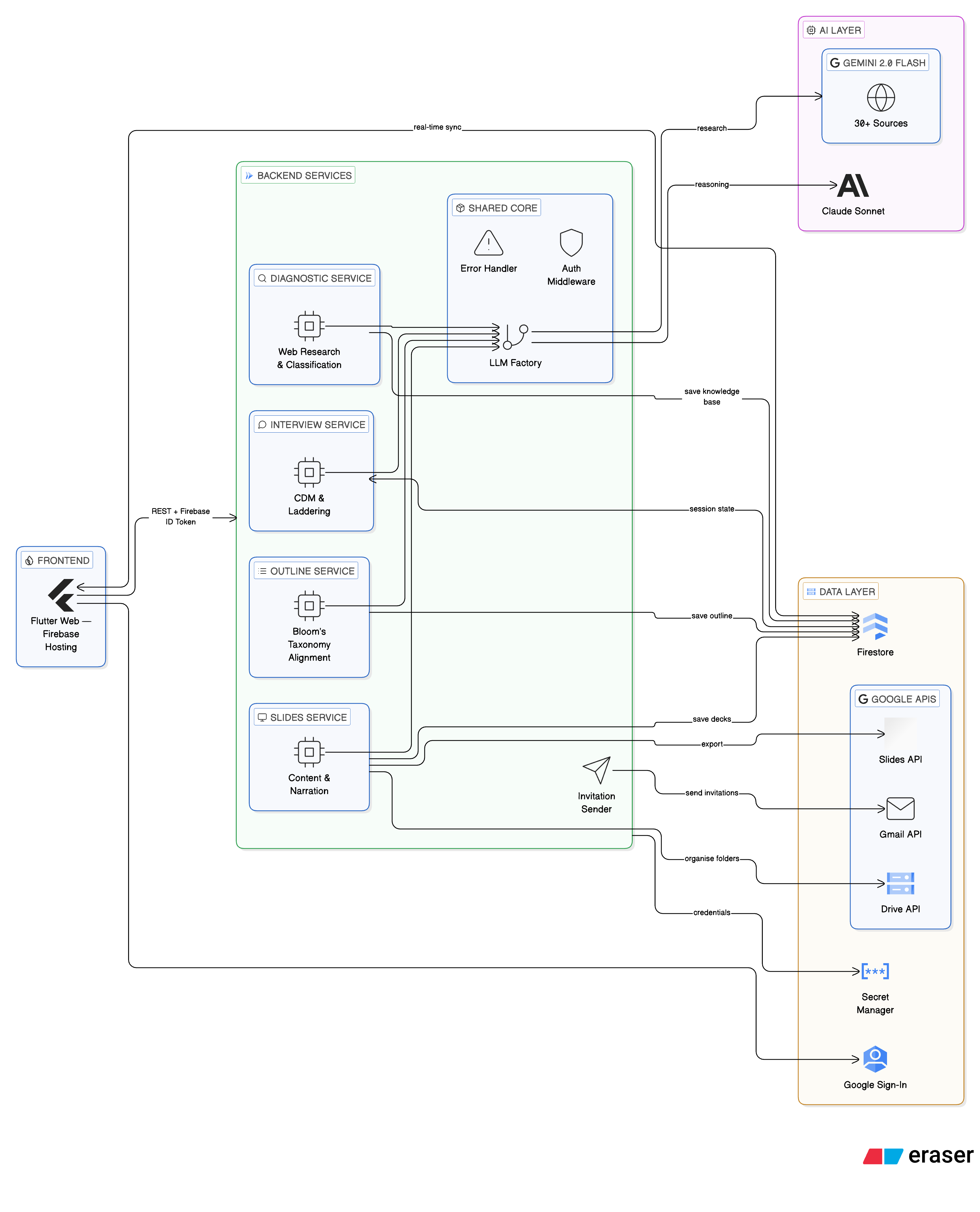
The Architecture
The system is built as a pipeline of ten specialised agents, each handling one phase of the course creation workflow. Agents are autonomous within their episode. Humans control the transitions between them.
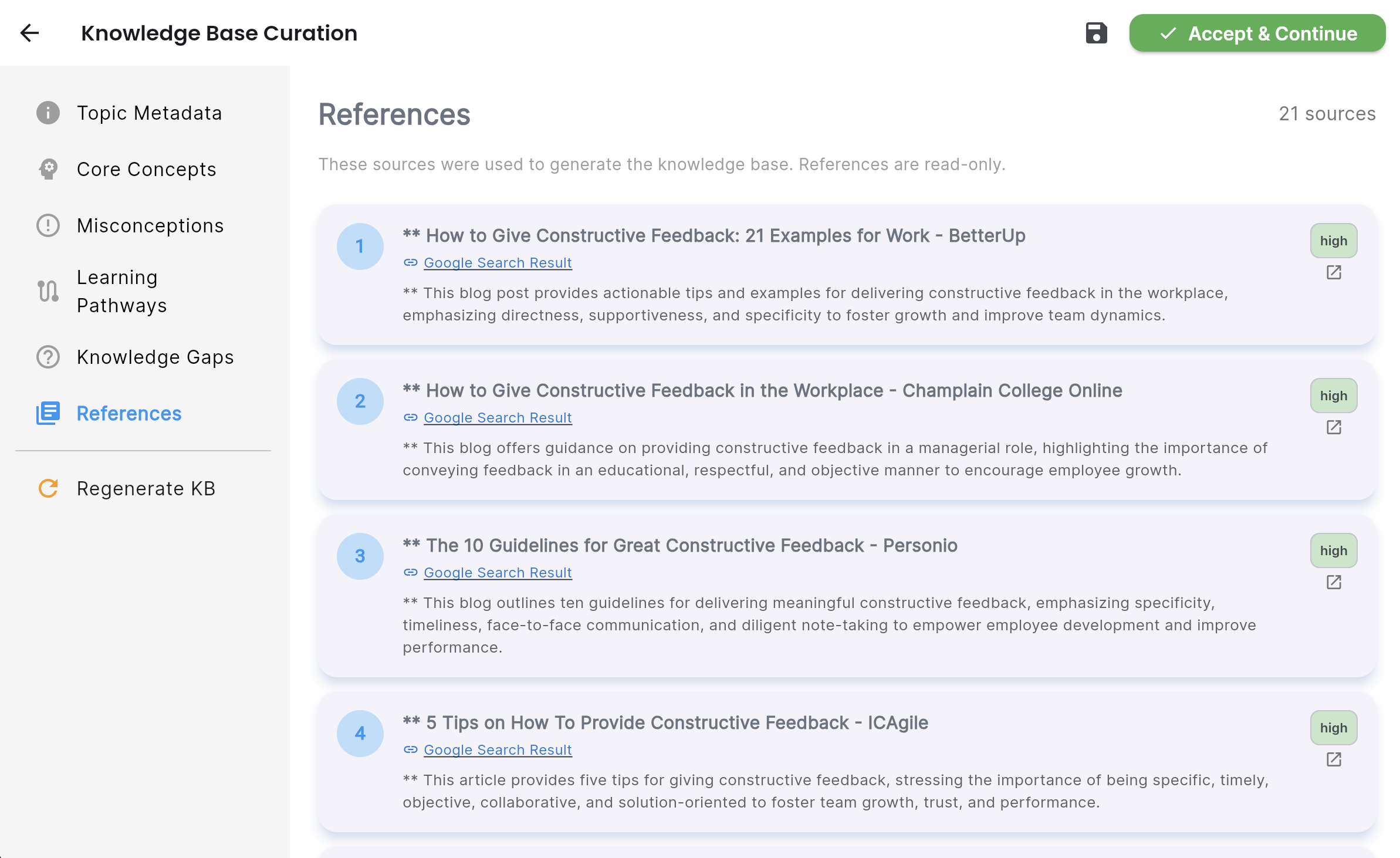
The Diagnostic Agent
The first agent does two things: it researches the topic comprehensively using Gemini 2.0 Flash with Google Search grounding (pulling from 30+ authoritative sources), and it classifies the knowledge type — procedural, conceptual, judgment-based, or mixed — with percentage breakdowns.
This classification is not cosmetic. It determines the entire downstream strategy. A procedural topic like “How to conduct a performance review” requires step-by-step demonstration and practice. A judgment-based topic like “When to escalate a client issue” requires case-based reasoning and deliberate exposure to edge cases. The questions the interview agent asks, the structure the outline agent builds, the depth the slide agent generates — all of it flows from this initial classification.
The Interview Agent
This is the centrepiece of the system, and the part I am most proud of.
Rather than asking the expert to fill in a questionnaire, the agent conducts a live, adaptive Socratic interview. It starts with the knowledge classification and the research base, identifies what the research cannot tell it — the tacit knowledge, the expert judgment, the experiential heuristics — and pursues those gaps through multi-turn conversation.
The agent uses techniques drawn from knowledge elicitation research: Critical Decision Method for surfacing expert reasoning in real scenarios, Laddering for uncovering the underlying principles behind expert choices, and deliberate challenging to test the boundaries of what the expert actually believes versus what they think they should say.
A typical interview runs 20 to 30 exchanges. The agent tracks coverage across the knowledge framework in real time, adjusting its questions as gaps close. When coverage meets the completion criteria, the agent concludes the interview and produces a structured set of knowledge nuggets — classified by type: expert insights, tacit knowledge, mental models, heuristics, identified misconceptions.
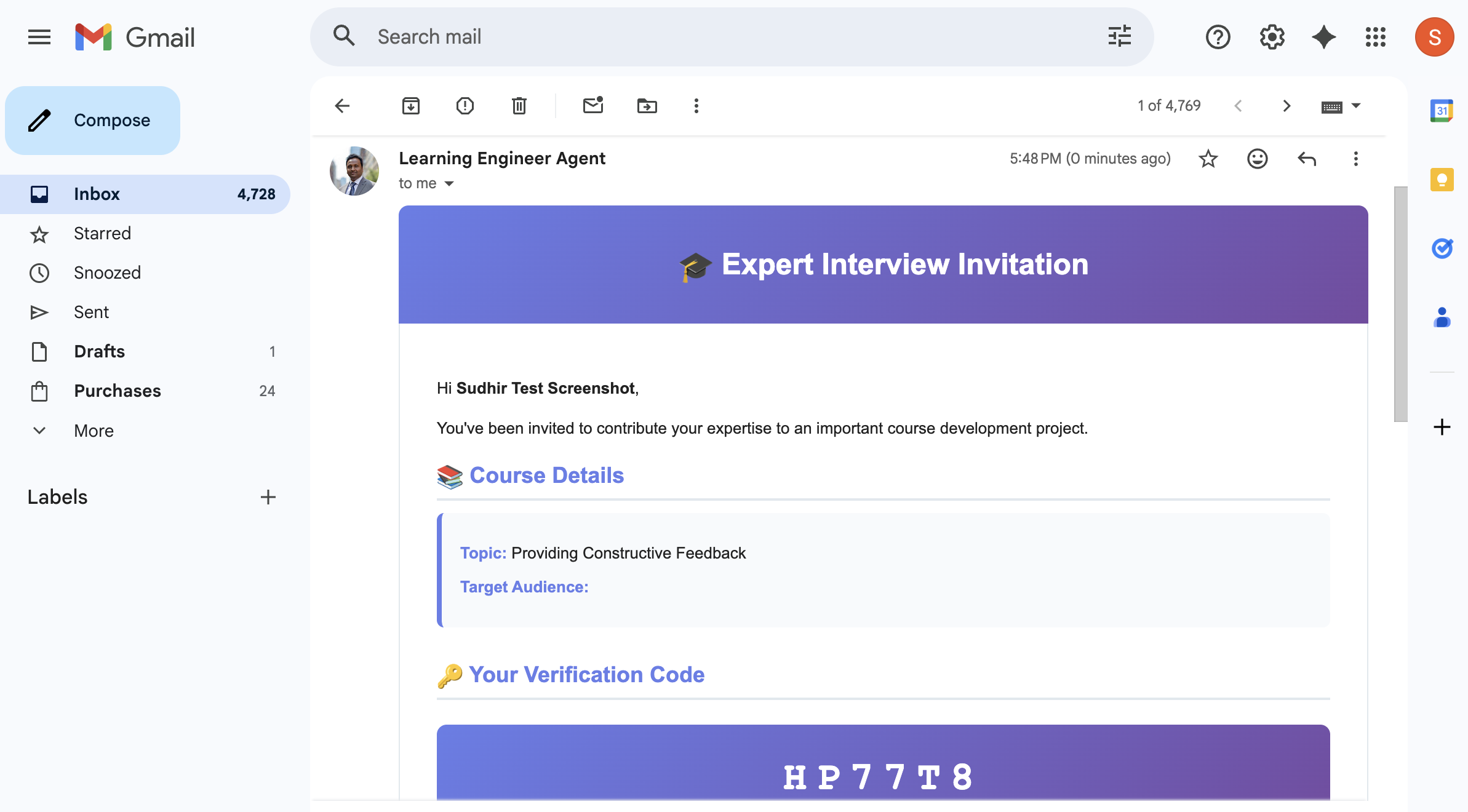
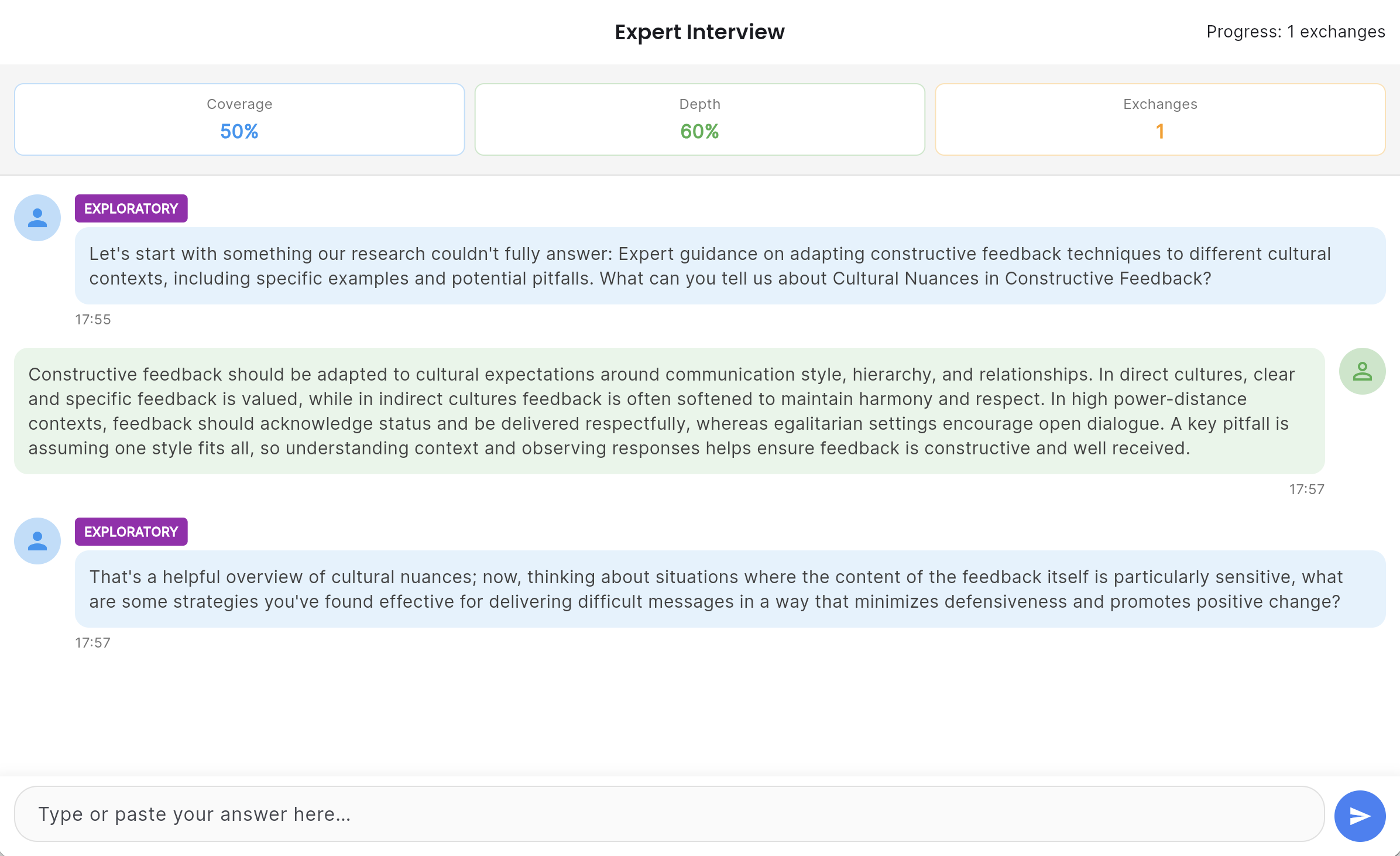
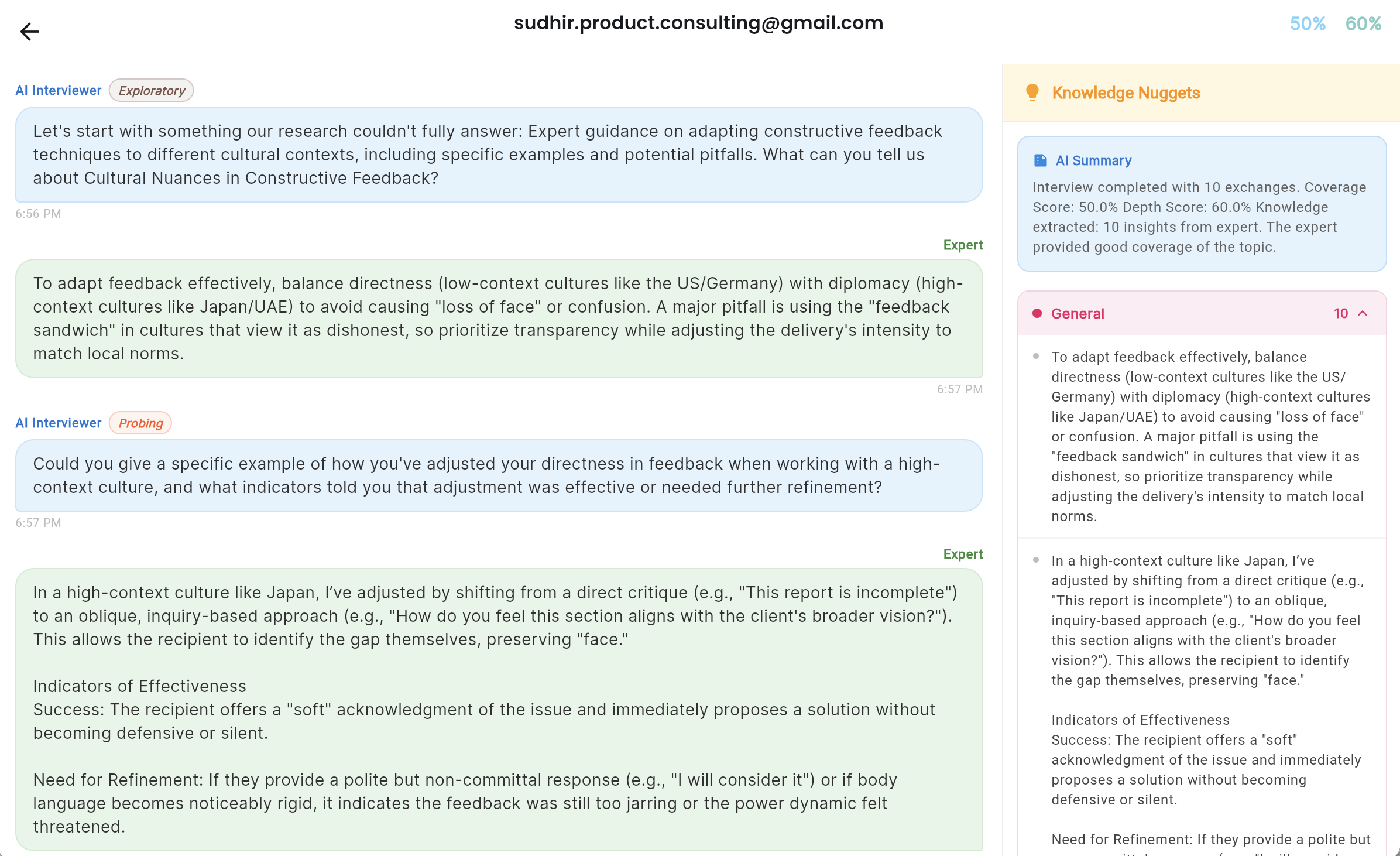
The course creator watches this interview happen in real time and can invite multiple experts for the same course.
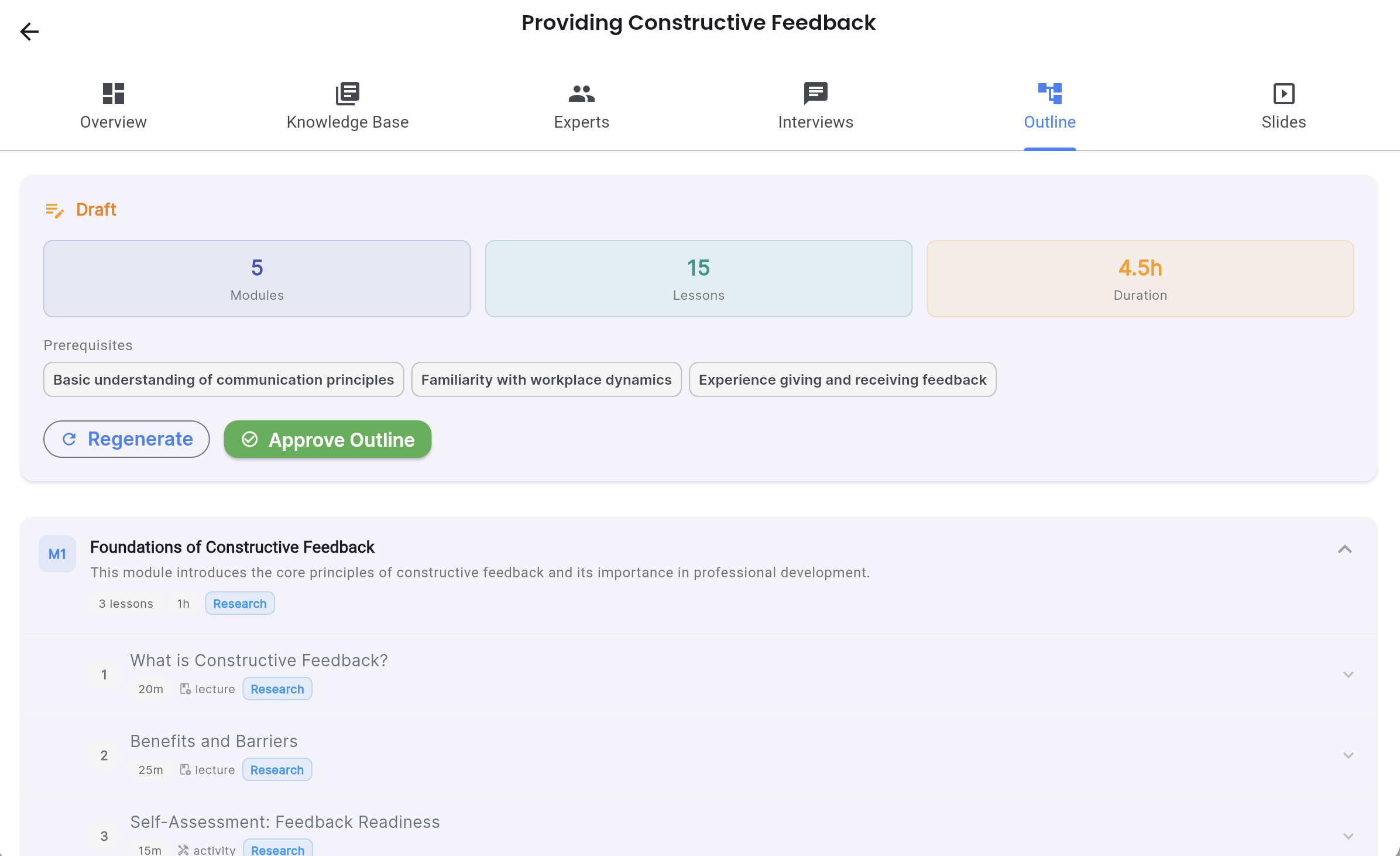
The Course Outline Agent
With the knowledge base and interview transcripts in hand, the outline agent structures a pedagogically sound course. It applies Bloom’s Taxonomy to sequence learning objectives, organises content into modules and lessons, and maps each piece of expert knowledge to the appropriate place in the learning journey.
The human reviews and edits this outline before anything else proceeds. Add a module. Remove a lesson. Reorder the sequence. Every edit is tracked and the AI version is preserved — you can always restore it.
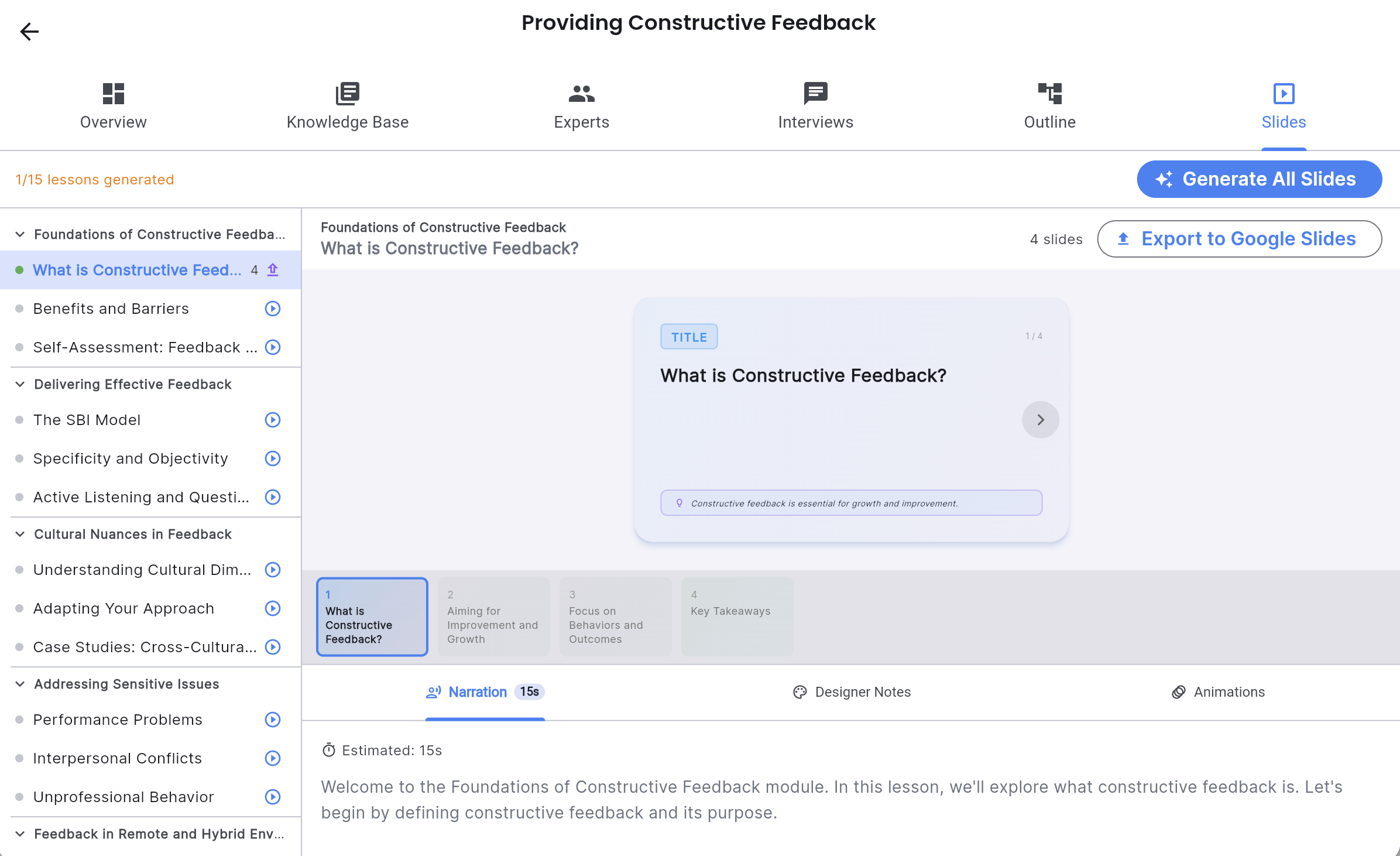
The Slide Generation Agent
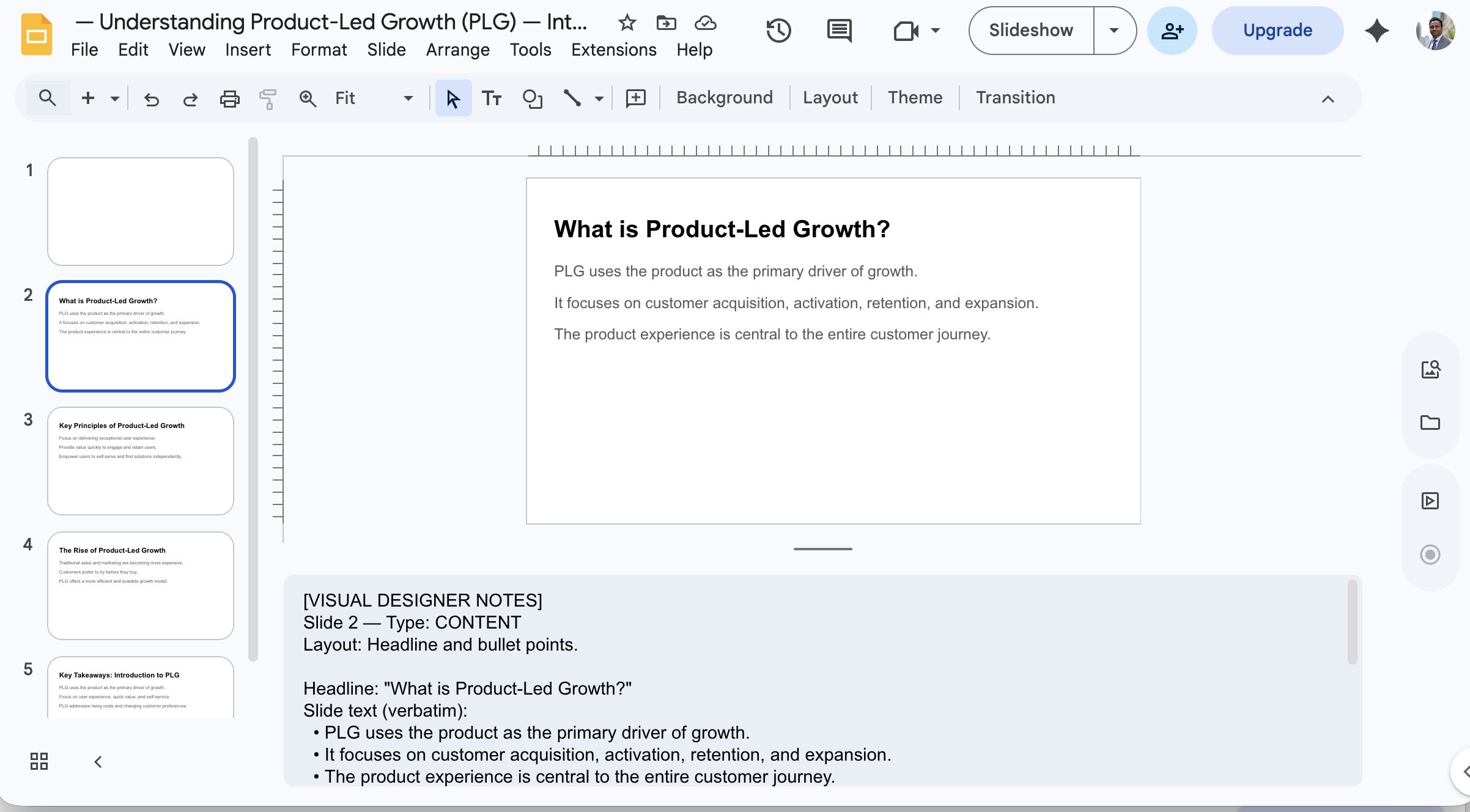
For each lesson, the agent generates complete slide decks: content, narration scripts, animation cues, knowledge check questions, and visual design specifications. It works from both the research base and the interview knowledge, weaving expert insights into slides at the appropriate moments.
Slides are stored in Firestore and viewable directly in the app with an in-app presenter before export. When the creator is satisfied, one click exports to Google Slides into an organised folder structure in their Drive.
Human-in-the-Loop at Every Stage
Every agent output is editable. Every edit is versioned. The AI never overwrites human changes, and every screen offers a “restore AI version” option if the human decides their edit was a wrong turn.
This is a deliberate design commitment, not a feature addition. The value of the system is not that it eliminates human judgment — it is that it handles the work that does not require human judgment, so the human’s attention is focused precisely where it matters most.
Beyond the Beta: Pipeline V2 in Active Development
The core insight driving the next phase: an agent earns its existence only if it has a genuinely different cognitive expertise from every other agent in the system. Not just a different task — a different reasoning mode, knowledge domain, or perspective on the problem.
The result is a redesigned pipeline orchestrated via LangGraph, with parallel lesson-level generation using map-reduce and human interrupt gates at high-leverage points.
| Agent | Expertise |
|---|---|
| DiagnosticAgent | Web research, knowledge base construction |
| InterviewAgent | Socratic expert interviews — tacit knowledge elicitation |
| KnowledgeSynthesisAgent ✦ | Maps expert insights to concept nodes, weights by depth score, flags expert-vs-research contradictions |
| CurriculumArchitectAgent ✦ | Prerequisite sequencing, pathway-differentiated course structures (novice / intermediate / advanced), Bloom’s objectives, assessment specs |
| PedagogicalDesignerAgent ✦ | Instructional strategy selection (worked examples, misconception-correction, scenario-based), content blueprints, Mayer’s multimedia principles |
| LessonResearchAgent ✦ | Optional deep research per lesson — targeted gap-filling informed by the instructional strategy |
| ContentAgent ✦ | Instructional writing from a fully-specified pedagogical brief |
| StoryboardAgent ✦ | Multimedia learning principles — designer-actionable visual specifications per content section |
| QAAgent ✦ | Constructive alignment audit per module — objectives ↔ content ↔ assessments |
| SlideAssemblyAgent ✦ | Assembles content + visual specs into final slide format |
✦ New or significantly redesigned in Pipeline V2
KnowledgeSynthesisAgent solves a problem that exists quietly in the current beta: tacit knowledge extracted from expert interviews gets diluted by the time it reaches content generation, weighted the same as a paragraph from a web article. This agent maps every interview nugget to the right concept node in the knowledge base, weights it by how deeply the expert engaged with that topic, and flags where expert knowledge contradicts the research. Downstream agents draw from one enriched knowledge base — not from research and interview separately.
CurriculumArchitectAgent introduces pathway differentiation. The knowledge base already identifies three learning pathways — novice, intermediate, advanced — each with different recommended sequences, typical backgrounds, and key obstacles. Pipeline V2 generates three genuinely different course architectures from the same knowledge base, each calibrated to the learner level.
PedagogicalDesignerAgent selects the instructional strategy for each lesson before ContentAgent writes a word. A lesson on a high-prevalence misconception gets a misconception-correction sequence. A procedural lesson gets worked examples with fading. A judgment-based lesson gets a scenario-based structure. This is where most of the output quality improvement will come from.
The LangGraph orchestration handles parallel lesson generation, conditional routing for quality failures, and human interrupt gates — the graph pauses, checkpoints to Firestore, and waits for approval before expensive generation steps begin.
What I Learned About the Limits of Autonomy
Building this system sharpened my thinking about AI autonomy in a way I did not expect.
The seductive version of this product — give it a topic, walk away, get a course — is achievable. I could remove the human review steps. The agents are capable enough. The output would be good enough for many purposes.
But “good enough” is the wrong standard for training content. And more importantly, removing the human from the loop removes the expert from the loop. The entire premise of the system is that expert knowledge is valuable and irreplaceable. An agent that bypasses the expert to generate a course from web research is not solving the original problem — it is building a more elaborate version of the thing I decided not to build.
The human-in-the-loop design is not a concession to the current limitations of AI. It is a product philosophy about what kind of knowledge is worth capturing and how.
Building Pipeline V2 reinforced a second lesson: the interesting design questions in multi-agent systems are not technical, they are cognitive. Which agent should select the instructional strategy — the one that knows the curriculum, or the one that knows learning science? Is assessment design part of curriculum architecture or a separate expertise? Where does content writing end and visual specification begin? Getting these boundaries wrong means agents doing too many different kinds of thinking at once, and each kind done poorly.
The architecture is a direct answer to those questions, worked out through building and failing and rebuilding.
Technical Stack
The system is built on a microservices architecture, with each agent running as an independent Cloud Run service. This keeps failure domains isolated and makes it possible to iterate on individual agents without touching the rest of the pipeline.
Frontend: Flutter Web, deployed on Firebase Hosting. Single codebase handles both course creator and expert interview flows. Google Sign-In only — necessary for OAuth token availability for Google Slides export.
Backend: Python services on Google Cloud Run. Shared agent code in a common library to avoid duplication across services.
LLM Strategy: Hybrid. Gemini 2.0 Flash handles research and web grounding — it is the best model available for tasks that require synthesising information from live sources. Claude Sonnet handles reasoning — interview question generation, pedagogical structuring, knowledge synthesis. Each model is doing what it is actually best at. Pipeline V2 adds Claude Opus for the PedagogicalDesignerAgent — the agent whose output quality most determines the quality of everything downstream.
Orchestration: LangGraph for Pipeline V2 — map-reduce parallelism at lesson level, checkpointing to Firestore, conditional routing for quality failures, human interrupt gates with resume capability.
Infrastructure: Firestore for real-time data and version management. Secret Manager for credentials. Firebase Authentication. Gmail API for expert invitations. Google Slides API and Drive API for export.
The Business Question
EdTech is a domain I have spent a significant part of my career in. The hardest part of building an education product is not the technology — it is earning enough trust from learners and institutions that they will actually use what you built.
Learning Engineer Agent addresses a different buyer than most EdTech products do. The customer here is not the learner. It is the organisation or individual who needs to create training content — and who currently either pays an instructional design agency a significant amount of money, or accepts that their internal experts’ knowledge never gets properly captured at all.
The system is currently in private beta. The business model is simple: one free course to experience the value, then pay-as-you-go credits for subsequent courses. No subscriptions to manage, no commitment required. Each credit deduction is visible by phase — Diagnosis, Interviews, Outline, Slides — so creators understand exactly what they are paying for.
The system serves two kinds of users. For subject matter experts who want to create their own courses, it handles the instructional craft they have not learned — structure, sequencing, pedagogy — while their expertise does the work only they can do. For instructional designers, it solves a different problem: the hardest part of their job is not designing courses, it is extracting knowledge from experts who are busy, inarticulate about their own tacit knowledge, or simply hard to get time with. The Interview Agent handles that extraction systematically and at scale, so the instructional designer can focus on what they are actually trained for.
Try It
The platform is live at learning-engineer-agent.web.app.
Sign in with Google. On the access screen, request a beta code via the form or reach out directly. I am keeping the initial cohort small — I want early users who will engage with the system seriously and share what they find, not just sign up and disappear.
A note on expectations: the current beta runs the core pipeline end-to-end — knowledge base, expert interviews, course outline, and narrated slides exported to Google Slides. The full 10-agent architecture described above, including pathway differentiation, pedagogical strategy selection, and LangGraph orchestration, is in active development. What is live today is a working, complete pipeline — not a prototype — but the architecture is where this is going.
If you are an instructional designer, L&D practitioner, researcher working on AI and education, or simply someone who has thought carefully about how expert knowledge gets captured and transferred — I would genuinely like to hear your reaction to what this system does and the choices I have made in building it.
Reflections
This project started as a personal exploration. I wanted to understand what it actually felt like to build a multi-agent system — not read about it, not prototype a toy version, but build something I would trust to run with real users and real content.
The most important thing I learned is that the interesting design questions in agentic AI are not technical. They are about where human judgment adds irreplaceable value, and where it just adds friction. Getting that boundary right is what separates a genuinely useful AI system from an impressive demo.
I started this project asking: what does agentic AI mean for EdTech?
My answer, after building it: it means AI that earns autonomy incrementally — by demonstrating reliable judgment in each episode, and by making it easy for humans to course-correct when that judgment falls short. Not an agent that does everything. A system that does the right things autonomously, and hands off the rest.
That feels like the right design for now. And I think it will remain the right design for longer than the current wave of AI enthusiasm tends to assume.
Technologies: Flutter, Python, Google Cloud Run, Firestore, Vertex AI, Anthropic Claude, Gemini 2.0 Flash, LangGraph, Google Slides API
Timeline: 2026 — Present
Status: Private Beta · Pipeline V2 in Active Development
Interested in AI-powered learning systems or the design of human-in-the-loop products? Let’s connect!
{kind=link}